

FuD ist ein netzbasiertes, modulares Softwaresystem, dass sich aus verschiedenen Systemen und Diensten zusammensetzt.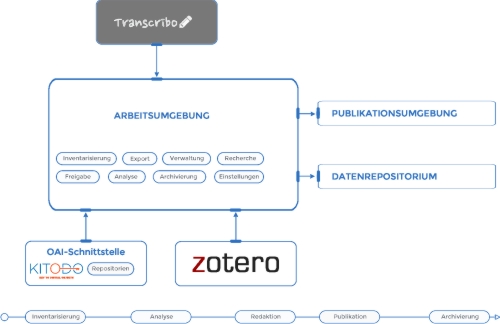
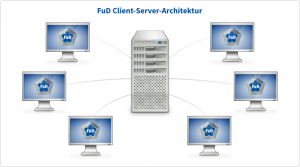 Für die Datenerfassung, ‑analyse und redaktionellen Aufbereitung wird die FuD-Arbeitsumgebung verwendet. Hierbei handelt es sich um eine Client-Server-Architektur (tcl/Tk, MySQL-Datenbank), wobei auf dem Arbeitsplatzrechner der FuD-Client installiert wird, mit dem die Daten auf dem FuD-Server bearbeitet werden. Den FuD-Client gibt es für aktuelle Windows- und in einer leicht reduzierten Form auch für Macintosh-Betriebssysteme. Diese Architektur erfordert während der Arbeit mit dem System eine permanente Internetverbindung zum Server.
Für die Datenerfassung, ‑analyse und redaktionellen Aufbereitung wird die FuD-Arbeitsumgebung verwendet. Hierbei handelt es sich um eine Client-Server-Architektur (tcl/Tk, MySQL-Datenbank), wobei auf dem Arbeitsplatzrechner der FuD-Client installiert wird, mit dem die Daten auf dem FuD-Server bearbeitet werden. Den FuD-Client gibt es für aktuelle Windows- und in einer leicht reduzierten Form auch für Macintosh-Betriebssysteme. Diese Architektur erfordert während der Arbeit mit dem System eine permanente Internetverbindung zum Server.
An die FuD-Arbeitsumgebung sind weitere Systeme wie Zotero für die Verwaltung der Sekundärliteratur oder das Transkriptionstool “Transcribo” für die Transkription von Volltexten angeschlossen. Dies wird je nach projektspezifischem Bedarf konfiguriert.
Über Importschnittstellen (XML, TXT, OAI) können bereits vorhandene, strukturierte Daten in die Arbeitsumgebung importiert werden.
Die Publikationsumgebung greift über eine JSON-Schnittstelle (Elastic-Search-Index) auf die Datenbank der FuD-Arbeitsumgebung zu. Sie basiert auf Angular und kann über aktuelle Browser (optimiert für Chrome und Mozilla) aufgerufen werden.
Die Archivierungsumgebung beruht auf dem Virtuelle Datenrepositorium “ViDa” für das aktuell eine Exportschnittstelle in der FuD-Arbeitsumgebung implementiert ist. Im Rahmen der Reimplementierung des ViDa-Systems werden zukünftig die Daten über den ViDa-Ingest Builder aus der FuD-Arbeitsumgebung nach ViDa importiert. Dies befindet sich aktuell im Aufbau.



